前言
在正式生产环境中,有时候会采用多个可用区以保障应用环境的高可用。
然后环境高可用了,应用也需要做到高可用,在多个可用区的情况下,我们需要平均在多个可用区中部署实例。
默认kubernetes中也支持可用区的分派,这里简单介绍一下。
亲和性
亲和性是优化调度的一种方案,可以解决以下问题:
- Pod固定调度到某些节点之上
- Pod不会调度到某些节点之上
- Pod的多副本调度到相同的节点之上
- Pod的多副本调度到不同的节点之上
这里我们的场景适用于第四个,多副本调度到不同的节点。
分配可用区
在默认初始情况下,集群节点是没有可用区概念的,所有的都在一个平面上,最多是以node为分割,如下图: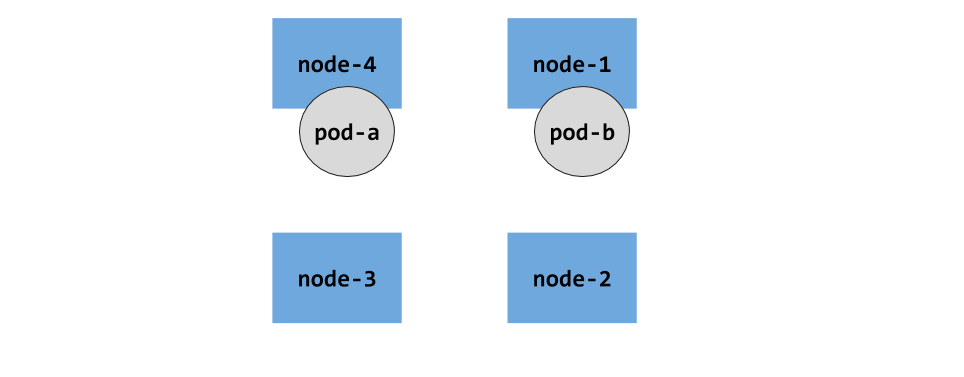
我们可以自己分配一下可用区,也就是以一组Node为单位,这里使用label来进行标记,默认集群Node状态为1个Master,4个Node。概况如下: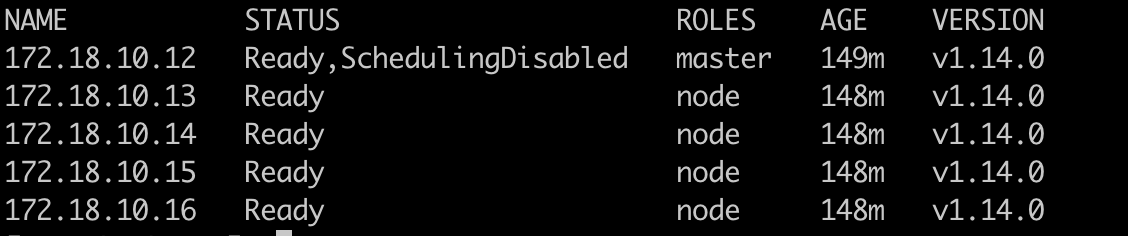
我们可以将13、14节点标记为可用区1,命名为az1,15、16节点标记为可用区2,命名为az2。使用以下命令进行标记:1
2
3
4kubectl label node 172.18.10.13 failure-domain.beta.kubernetes.io/zone=az1
kubectl label node 172.18.10.14 failure-domain.beta.kubernetes.io/zone=az1
kubectl label node 172.18.10.15 failure-domain.beta.kubernetes.io/zone=az2
kubectl label node 172.18.10.16 failure-domain.beta.kubernetes.io/zone=az2
分配过后的节点拓扑结构大致如下: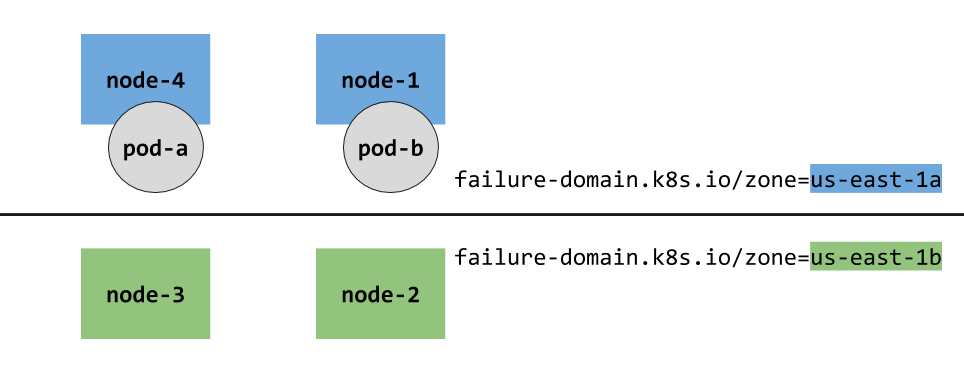
最后可以通过以下命令查看到可用区配置:kubectl get node --show-labels

如果配置错了,也可以通过以下命令进行删除:kubectl label node 172.18.10.13 failure-domain.beta.kubernetes.io/zone-
修改node后面对应的IP即可。
亲和性配置
可用区已经分配好了以后,还需要配置一下部署的亲和性,只需要在Deployment的template字段下面添加以下配置即可:1
2
3
4
5
6
7
8
9
10
11
12affinity:
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 100
podAffinityTerm:
labelSelector:
matchExpressions:
- key: name
operator: In
values:
- nginx
topologyKey: "failure-domain.beta.kubernetes.io/zone"
其中labelSelector下面的匹配规则需要根据实际的情况来,需要与template下面的metadata→labels对应。
完整的示例如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx
labels:
name: nginx
spec:
replicas: 3
selector:
matchLabels:
name: nginx
template:
metadata:
labels:
name: nginx
spec:
affinity:
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 100
podAffinityTerm:
labelSelector:
matchExpressions:
- key: name
operator: In
values:
- nginx
topologyKey: "failure-domain.beta.kubernetes.io/zone"
containers:
- name: nginx
image: "nginx:alpine"
imagePullPolicy: IfNotPresent
ports:
- name: http
containerPort: 80
当我们指定亲和性配置以后,这里最终调度也会分为几种情况:
- 当我们指定的副本实例数量为1,也就是小于可用区时,最终调度会根据可用区资源情况,随机分配
- 当我们指定副本实例数量为2,也就是跟可用区相同时,最终就会分别在两个可用区中运行着2个副本实例
- 当我们指定副本实例数量大于2,也就是大于可用区数量时,最终会先分别在可用区中调度副本,然后根据资源使用情况,在某个可用区中部署多个副本。
测试
最后我们根据上面的示例,运行一下测试看看。
副本小于可用区
首先我们把副本数量(replicas)调整为1,也就是小于可用区数量,看看调度情况: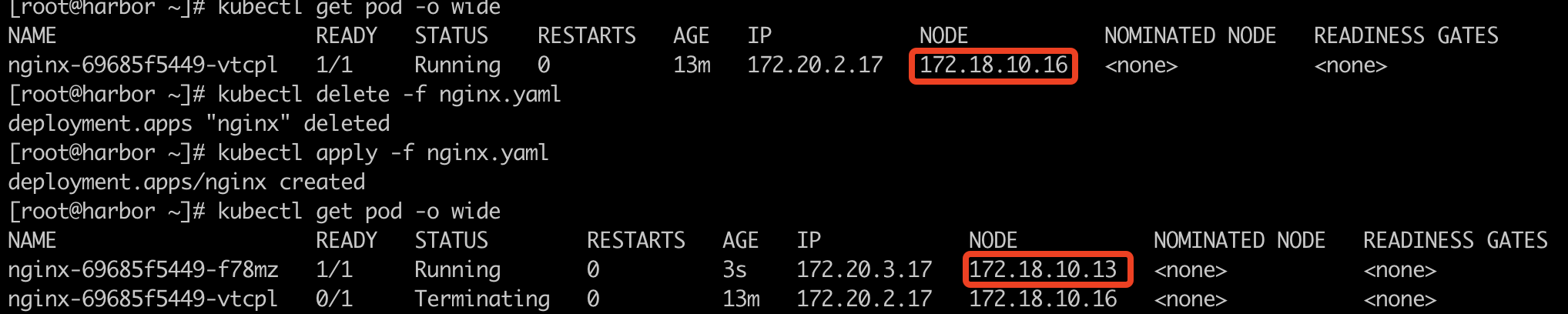
根据上面截图,可以看到,第一次调度在az2的可用区内,第二次调度在az1的可用区内了。
副本等于可用区
接下来我们再把副本数量调整为2,也就是等于可用区数量,看看调度情况: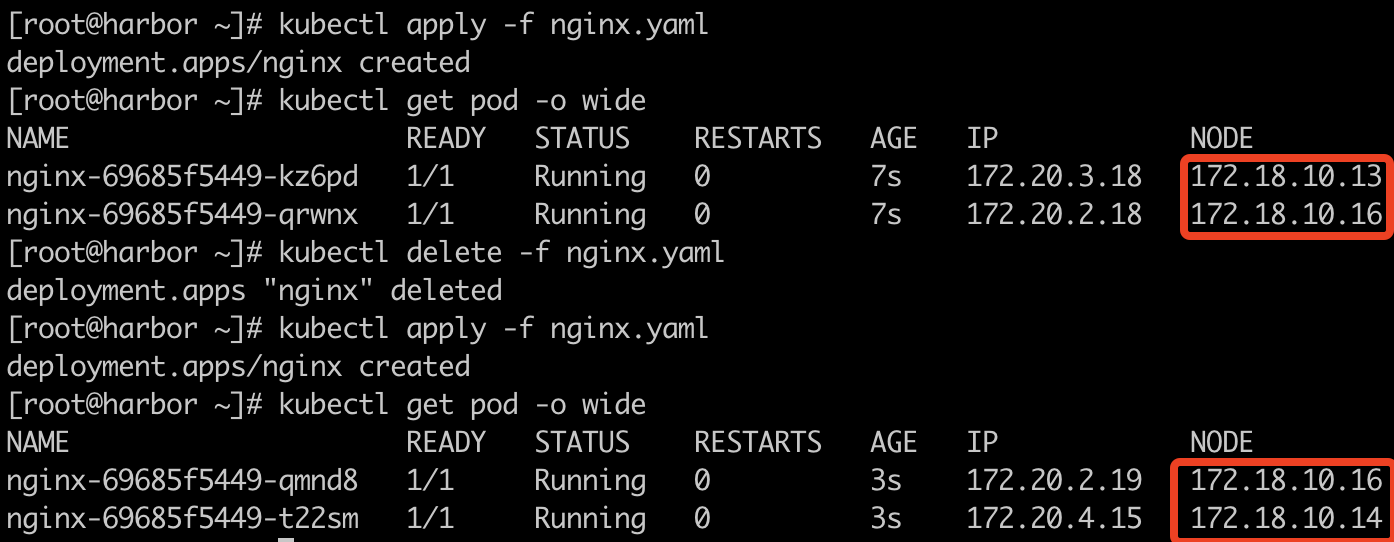
根据上面截图,我们可以看到,不管我们重新部署几次,始终是分别平均调度在两个可用区内的。注:当副本数量大于可用区的倍数时,也会进行平均调度。
副本大于可用区
最后我们再测试一下,副本大于可用区数量时的情况,这里我们将副本设置为3看看调度: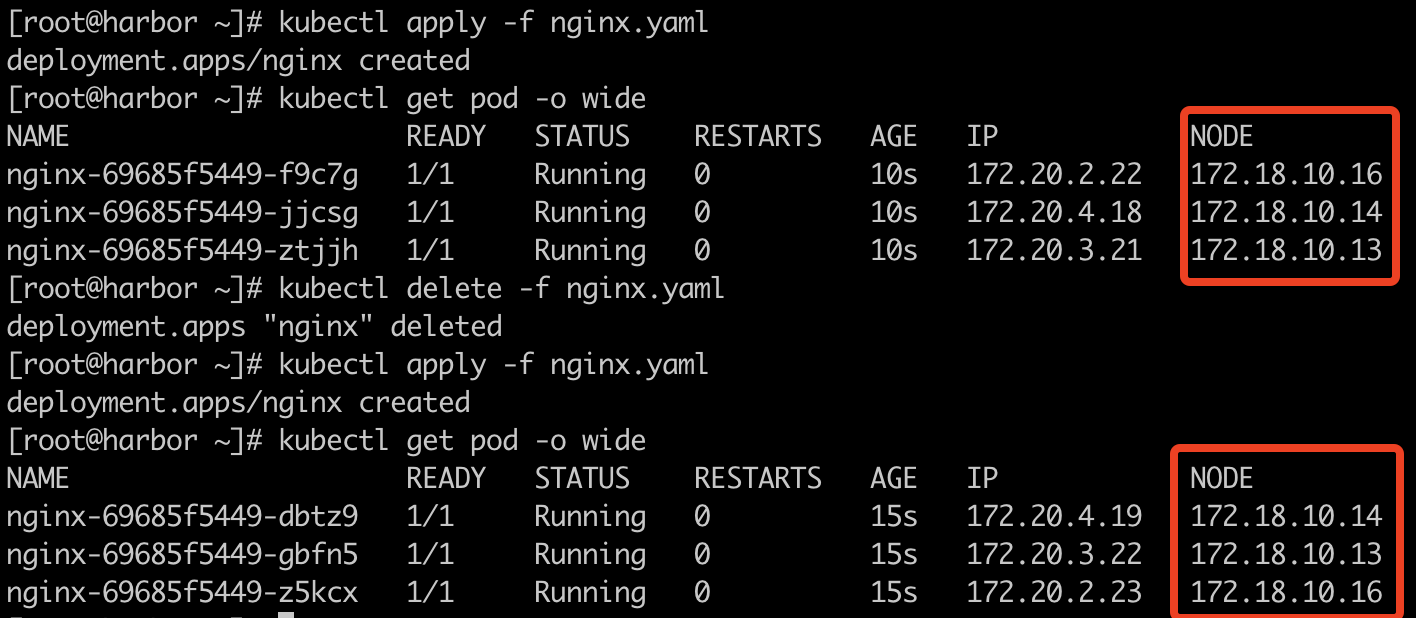
根据实际的调度情况,可以看出首先确实是平均在可用区运行了,多的则根据资源情况选择可用区进行运行。
这也验证了我们一开始定下来的结论。
尾声
这里对于亲和性的使用还是属于比较简单的一种,但却是比较实用的。更多的场景待我们后续再慢慢可以补充。
